Интересная статья на тему "звук вокруг" . История, аппаратура, программное обеспечение, теория, искуственная голова, стерео, квадро, 3D.
Рис. 1. Стереопанорама
Большинство современных дешёвых и не очень звуковоспроизводящих устройств включая звуковые карты для персональных мультимедиа компьютеров позволяют воспроизводить звук в режиме “3D Sound” или “Suround”, что можно перевести как “объёмный звук”.
Что же это такое и для чего это нужно? Системы объёмного воспроизведения звука были разработаны потому, что качество звучания, реализуемое обычной стереофонической системой или головными телефонами, перестало удовлетворять взыскательных слушателей. Хотя стерео системы и создают эффект пространственного звучания за счет синтеза панорамы мнимых источников звука (МИЗ) между двумя громковорителями (рис. 1), все же стереозвучание имеет существенный недостаток. Стереопанорама получается плоской и ограничена углом между направлениями на громкоговорители. Такое звучание в значительной степени лишено естественности, свойственной тому, что достигается в реальном звуковом поле, когда человек способен воспринимать реальные источники практически со всех направлений как в горизонтальной так и в вертикальной плоскостях и оценивать, хотя порой и с ошибками, расстояние до источников звука.
Считается, что восприятие звуков с разных направлений и расстояний имеет важное значение не только как факт их пространственного расположения. Оно создаёт у слушателя ощущение звучащего объёма (трёхмерного звукового поля), существенно обогащает тембры музыкальных инструментов и голосов, восстанавливая реверберационный процесс, свойственный первичному помещению (концерному залу). Обычная стереофония создаёт эффект пространственного звучания в очень ограниченной области перед слушателем, не позволяет в полной мере выявить названные особенности восприятия звуков в реальном звуковом поле и, следовательно, снижает качество звучания.
Квадрофонические системы также не обеспечивают полную имитацию реального звукового поля. Во-первых, при квадрофонии не получается круговая стереопанорама - слушатель ощущает обычную стерео панораму перед собой и заднюю стерео панораму сзади себя. Во-вторых, все мнимые источники звука располагаются в одной плоскости и на линии между динамиками, т.е. нет глубины и нет, собственно, 3-го измерения и трёхмерного объемного звучания (Рис. 2).
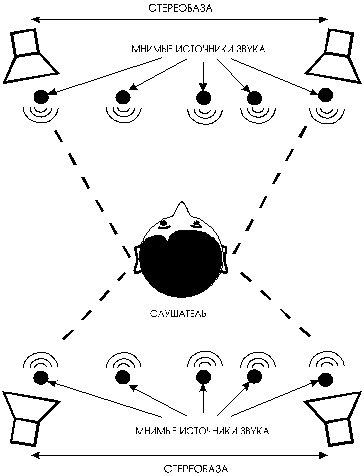
Рис. 2. Квадропанорама
Головные стерео телефоны также не позволяют получить естественное звучание воспроизводимой фонограммы. Дело в том, что возникающее при этом впечатление бесконечной ширины стереобазы и четкая локализация звукового изображения внутри головы слушателя не могут удовлетворить требовательных меломанов. Для устранения эффекта локализации звука внутри головы применяются схемы подобные приведенной на Рис. 3.

Рис. 3. Блок схема устройства создания объемного звука для стереотелефонов
Здесь сигналы левого и правого каналов через входные устройства А1 и А2 поступают соответственно на делители напряжения А3 и А6 и на входы перекрестных каналов, состоящих из линий задержки (ЛЗ) А4, А5, согласующих устройств А8, А9 и фильтров нижних частот (ФНЧ) Z1, Z2. С делителей А3, А6 сигналы подаются на корректоры АЧХ А7 и А10 и далее - на один из входов сумматоров, а с них - на входы усилителей мощности для стереотелефонов. Таким образом, на выходе каждого канала формируется сигнал, состоящий из ослабленного и скорректированного сигнала своего канала и задержанного и соответствующим образом скорректированного сигнала другого канала.
Подобными устройствами, выполненными в виде приставок или встроенных устройств в настоящее время оснащены многие музыкальные центры. Интересно, что такие устройства могут быть реализованы и чисто программными методами с использованием цифровой обработки сигналов в реальном времени. Читатели, имеющие персональный компьютер с фулдуплексной звуковой картой (к сожалению программа плохо работает с картами производства сингапурской фирмы Creative Labs.), могут скачать одну из подобных программ из Интернет с сервера www.geocities.com/SunsetStrip/Palladium/2932/v108.zip. Программа с этого сервера кроме того позволяет добавить эффекты реверберации для маленького, среднего и большого помещения, эхо, хорус, флэнжер и имеет довольно неплохой эквалайзер, значительно улучшающий воспроизведение низких (20..60 Гц) частот через стереотелефоны среднего класса качества. Все эффекты работает в реальном времени даже на очень дешевых звуковых картах без DSP процессоров, например на OPTi-931 или Acer S23.
Наиболее совершенный метод имитации реального трёхмерного звукового поля это Бинауральная передача звука. Бинауральный метод состоит в том, что звуковая информация воспринимается микрофонами, размещёнными в ушных раковинах человека или “искусственной головы” - модели, симулирующей слуховое восприятие человека. Сигналы, поступающие с каждого микрофона, усиливаются раздельными усилителями низкой частоты и воспроизводятся стереотелефонами. В идеале такая система позволяет создать полную иллюзию естественного звучания.
Она как бы переносит слушателя из помещения прослушивания в помещение, откуда ведётся передача. Однако полноценно прослушивать её можно только с помощью стереотелефонов и при условии что в качестве образца для создания искусственной головы использовалась именно ваша голова. Читатели могут прослушать бинауральные демонстрационные звуковые WAV файлы, скачав их через Интернет с серверов www.lakedsp.com, www.wа.com.au/lake, www.3daudio.com, www.geocities.com/SiliconValley/Pines/7899, www.geocities.com/SunsetStrip/Palladium/2932/3d_audio.htm
При воспроизведении бинаурального сигнала через звуковые колонки из-за попадания сигнала правого канала в левое ухо слушателя и наоборот возникают перекрёстные искажения, в конечном счёте сводящие на нет все преимущества бинаурального звуковоспроизведения. Указанные недостатки в значительной мере удаётся устранить с помощью специального устройства обработки звуковых сигналов, позволяющего получить бинауральный эффект при прослушивании бинауральной записи через колонки. Такие устройства получили название бифонических процессоров. Запись производится с микрофонов, расположенных в искусственной голове, а воспроизводится после обработки бифоническим процессором, в котором точно рассчитанная величина сфазированного, задержанного и скорректированного по частоте сигнала левого канала вычитается из сигнала правого канала и наоборот. Структурная схема бифонического процессора, впервые разработанного фирмой JVC, показана на рис. 4.

Рис. 4. Блок схема бинаурального процессора
Он состоит из усилителей сигналов левого и правого каналов А1, А2, усиливающих сигналы с микрофонов, установленных в искусственной голове А0, линий задержки D1, D2, фазовращающих устройств U1, U2 и сумматоров Е1, Е2. После обработки бифоническим процессором сигналы, приходящие из колонок в уши слушателя суммируются так, что левое ухо слышит только сигналы левого канала, а правое - правого канала. Таким образом, можно сказать, что бифонический эффект подобен бинауральному и отличается от него только способом воспроизведения бинауральной записи.
И хотя площадь, где он отчётливо проявляется, невелика, зато, находясь в её пределах, слушатель может иметь представление о расстоянии до источников звука и их взаимном расположении в пространстве в момент записи, чего не удаётся достигнуть при стереофоническом звуковоспроизведении, дающем представление только о расположении источников звука на линии между звуковыми колонками. Другое интересное свойство бифонического процессора - это возможность расширения с его помощью стереобазы обычных стереофонических записей.
Именно это обычно и имеется ввиду под “3DSound”. А если сиcтема позволяет увеличить мнимый угол между направлениями на звуковые колонки (Рис.1) до 180 градусов, то такую систему называют “Suround” и создаваемая звуковая панорама для неё будет такой же как при прослушивании на стереотелефоны, но без концентрации мнимых источников звука внутри головы слушателя. Конечно, бифонический процессор может быть реализован чисто программными методами с использованием методов цифровой обработки сигналов в реальном времени.
Читатели, имеющие персональный компьютер с фулдуплексной звуковой картой, могут скачать одну из подобных программ из Интернет.
Данная статья основана на моей дипломной работе по теме «Разработка принципов имитации объемного звучания в развлекательной сфере», кафедра информационных технологий, МАИ 2011 год. Для адаптации текста вырезаны сухие статистические данные, язык сделан более живым, вставлены отсылки к книгам и статьям, которые я могу порекомендовать. Затронутые вопросы будут интересны тем, кто еще только изучает механизмы локализации звука. Программная часть в статье не затрагивается. Для дополнительного интереса из статьи не вырезана практическая часть создания бинаурального манекена-микрофона.
Хочу выразить благодарности Борису Климову за создание эксклюзивных иллюстраций, а так же Надежде Гурской за анализ и правки текста.
Введение
Основная цель виртуальной реальности «погрузить» человека в пространство игры, действия на экране (фильм, мультфильм, 5D кинотеатр) настолько, чтобы на время он забыл о реальности мира окружающего.
О понятиях «Immersion», а так же «Suspension of Disbelief» по отношению к звуку и музыке можно прочитать в книге Winifred Phillips – A Composer’s Guide to Game Music.
Объемное звучание – залог того, что человек сможет ощутить эффект «присутствия». Восприятие звукового пространства, очевидно, было востребовано еще задолго до появления средств записи звука: на протяжении веков создавались помещения, такие как храмы, театры, концертные залы, где обеспечивалось «погружение» слушателя в звуковое пространство путем создания естественного акустического эффекта - реверберации. Научные исследования поведения акустики в концертных залах фирмой «Bose» показали, что приблизительно 11% доходит до слушателя напрямую, остальной процент звука приходит в отраженном виде от стен, пола и потолка и других объектов вокруг слушателя, тем самым создавая объем звука. С информативной точки зрения 25% информации об окружающем мире, получаемой человеком, приходится на звук.
Подход к звуку в современных кинотеатрах приучает слушателя к тому, что звук может и должен быть качественным и реалистичным. Профессиональными разработчиками современных игровых приложений работе со звуком отводится до 40 процентов бюджета и временно-людских ресурсов. С другой стороны некоторых разработчиков игр и приложений ещё надо убедить потратить время и средства на реализацию качественного звука.
На тему различных подходов интересно почитать статьи «Озвучивание компьютерных игр» 1 и 2 части от Кристофера (свободно ищется в интернете).
Восприятие звука человеком
Человеческий слух способен воспринимать звук в диапазоне от 16-20 Гц до 15-20 кГц. Звуки с частотой ниже 20-30 Гц (инфразвук) воспринимается не органом слуха, а осязанием, например, через вибрацию поверхностей. Частоты предельных нижних значений слышимого спектра могут восприниматься через резонансы внутренних органов человека. При небольшой интенсивности звук низкой частоты оказывает дополнительное эмоциональное воздействие (например, популярный эффект sub drop).
Уменьшение диапазона слышимых частот связано с изменениями во внутреннем ухе и с развитием возрастной нейросенсорной тугоухости. К 60-и годам слышимый диапазон на верхней границе становится не выше 10-12 кГц. Так как основной контингент развлекательной сферы люди молодые, то воспринимаемый слухом диапазон должен учитываться в полной мере. Но и специалист по звуку должен обладать полноценным слухом, слышать неестественность и неполноту тембра, мочь выявить резонансы. И что не маловажно - беречь слух от перегрузок. Многие люди в музыкальной-звуковой сфере испытывают постоянные нагрузки от звукоусиливающей техники и громких акустических инструментов (как и я сам, за более чем 12 лет игры на ударных инструментах). Современный человек подвержен негативному воздействию окружающих шумов, что снижает его чувствительность, притупляет верхние границы частот раньше естественной тугоухости. Не нужно пренебрегать такими средствами защиты слуха, как беруши. Также негативное влияние могут оказывать звуки низких частот.
Подробно с негативным воздействием звука (в том числе технического) можно ознакомиться в книге Чедд Г. – Звук.
Восприятие звука индивидуально, оно зависит от конфигурации (формы) ушной раковины, физиологических особенностей, возраста и от психологического настроя в конкретный момент. В рассматриваемой сфере восприятия звука также зависит от:
- средств воспроизведения (динамики воспроизводящего устройства, наушники, колонки, многоканальные системы),
- помещения в котором осуществляется прослушивание,
- качества средств преобразования (например, реализация звукового процессора, движка),
- соблюдения принципов создания правильной звуковой картины, если речь идет о саунд-дизайне.
Механизмы локализации источника звука человеческим слухом
Способность человека локализовать источник звука в пространстве строится на принципе бинаурального слуха. Бинауральное (от лат. bini - «два» и auricula - «ухо») строение слуховой системы заключается в различном восприятии звуковых сигналов пришедших на правое и левое ухо. Алгоритм локализации источника звука:
- звуковой сигнал, исходящий от источника звука и переотражений помещения, попадает во внешнюю часть слуховой системы, где конфигурация ушной раковины позволяет передать во внешний слуховой канал уже частотно обработанный сигнал,
- сигнал проходит в барабанную перепонку человека, в силу вступают механизмы внутреннего уха,
- из внутреннего уха информация поступает в отделы головного мозга, где на основе анализа сравнения сигналов, поступивших с каждого из слуховых каналов, делаются выводы о расположении звукового источника.
Человеческий мозг сравнивает информацию, пришедшую из барабанных перепонок, с той информацией, которая уже хранится в памяти.
Рис. 1. Строение внешней части слуховой системы человека
Подробно об устройстве внешнего и внутреннего слуха и о многих другом можно прочитать в книге Ирины Алдошиной и Роя Приттса – Музыкальная Акустика, глава «Восприятие звука. Основы психоакустики»
Для определения месторасположения звукового источника в пространстве слуховая система использует основные механизмы локализации: по разнице во времени, по разнице интенсивности, по разнице амплитудно-частотного спектра. К вспомогательным механизмам относятся отражения звука от туловища и плеч человека, реверберация, окклюзии (звук, прошедший через препятствие), обструкции (звук отфильтрованный препятствием), эффект Доплера, эффект Хааса (эффект предшествования). Не стоит забывать про эффект психологического восприятия: при несоответствии источника в видимом пространстве со звуком или нарушении синхронности качество локализации резко падает.
Определять пространственное положение источника звука приходится при наличии звуковых помех. Существуют естественные механизмы помехоустойчивости слуховой системы. Один из них проявляется в бинауральном освобождении от маскировки. Феномен состоит в том, что локализовать звуковой сигнал на фоне статичных помех (например, шумов окружения) легче.
Пару слов о прозрачности звучания. Приведу известный пример. Представим несколько контурных рисунков животных, наложенных друг на друга. Опознавание совмещенных в пространстве рисунков тем сложнее, чем ближе формы изображенных животных (термин форма имеет тот же смысл, что и в звуковом сигнале). Если же эти рисунки разнести в пространстве, то задача определения животного по форме становится значительно проще.
Локализация по временной разнице (фазовая локализация)
Данный механизм работает на частотах от 300 Гц до 1,5 кГц. За счет разницы между положением левого и правого уха звук, приходящий от источника, расположенного под углом к фронтальному направлению, затрачивает различное время для достижения барабанных перепонок.

Рис. 2. Схематичный пример фазовой локализации
При одинаковом времени, затрачиваемом для достижения сигнала левого и правого уха, данный механизм будет локализовать источник в азимуте 0 и 180 градусов. Различное время достижения барабанных перепонок приводит к появлению фазового сдвига. Слуховая система различает фазовый сдвиг до 10-15 градусов. С повышением частоты, а соответственно, с уменьшением длины звуковой волны, фазовый сдвиг сигналов, пришедших от одного и того же источника к разным ушам, увеличивается. Как только сдвиг достигает значения, близкого к половине длины звуковой волны механизм перестает работать. Человеческий мозг не может однозначно определить, отстает ли звуковой сигнал в одном из слуховых каналов от другого или, наоборот, опережает его.
Максимальная разница во времени, соответствующая полному смещению источника звука вправо или влево, не может быть больше 630 мкс.
Расстояние между правым и левым ухом взрослого человека составляет 0,15 м-0,20 м, если брать среднее значение по полу. При источнике, излучающем звуковую волну с частотой 20 Гц и скорости звука в 340 м/с, длина волны будет составлять 17 м. Соответственно, если человек повернется к источнику одной стороной, то фазовый сдвиг сигналов, пришедших в одно ухо, а затем в другое, будет составлять примерно 1,1 % от всего периода 20 Гц волны (локализации на таких низких частотах невозможна). Физиологически точность локализации зависит от размера головы, то есть расстояния между ушами. Чем больше это расстояние, тем с большей разницей приходят звуковые сигналы в каждое ухо.
При излучении звука источником, расположенным под определенным углом к фронтальному направлению, уровень звукового давления на барабанные перепонки в разных ушах будет различным. Это связано с тем, что одно ухо будет находиться как бы «в тени», которую создает голова, а также с тем, что звуковые волны выше 1000 Гц сравнительно быстро затухают в пространстве.

Рис. 3. Схематичный пример локализация по уровню интенсивности
Данный механизм является достаточно эффективным, но в диапазоне звуковых частотах от 1600 Гц. При длине звуковой волны, сравнимой с диаметром человеческой головы, дальнее от источника ухо перестает находиться в «акустической тени», что обусловлено явлением дифракции звуковой волны на поверхности головы. При этом опытным путем было выявлено, что способность человеческим слухом определения угла между двумя источниками в горизонтальной плоскости в области частот 1500-2000 Гц резко снижается.
Такой механизм способствует определению расстояния до источника звука. Однако уровень звука от слабого, но близко расположенного источника может быть таким же, как от мощного, но удаленного на значительное расстояние. При таких условиях локализации способствует следующий механизм.
Локализация по разнице амплитудно-частотного спектра
Механизм основывается на возможности анализа мозгом АЧ провалов и подъемов определенных частот в сложном сигнале. Звук, приходящий под углом 90°, содержит как низкочастотные, так и высокочастотные составляющие, а в спектре звука, действующего на дальнее ухо, высокочастотных составляющих будет меньше - экранирующее воздействие головы. Кроме того, звуковой сигнал по-разному отражается от участков ушной раковины, происходит усиление и ослабление различных участков звукового спектра.
Данный механизм отвечает за локализацию фронт-тыл и вертикальную плоскость. Изучение фильтрующего действия головы и ушных раковин слушателя позволило ввести понятие пеленговых полос. При локализации человек анализирует не весь спектр приходящего звука, а лишь изменения некоторых частот. Такие полосы сформировались эволюционно, слух выработал собственную систему отслеживания и предупреждения опасности, достаточно точно локализуя откуда исходит угроза.
Изменения в полосах от 16 до 500 Гц и от 2 до 6 кГц отвечают за локализацию передних источников звука. Полоса от 0,7 до 2 кГц - изменение тембра источников, которые могут располагаться сзади.
Сигнал со сложным спектральным составом локализуется лучше, а ощущение направления «фронт-тыл» формируется преимущественно теми полосами направления, в которых сосредоточена большая часть мощности сигнала. Чистые тона, которые, практически не встречаются в природе локализуются хуже сложных сигналов. Так, чистые тона свыше 8000 Гц поддаются локализации с трудом. Невозможно определить и местоположение источников звука низкой частоты - менее 150 Гц.
Локализация в вертикальной плоскости гораздо хуже, чем в горизонтальной. Без психологического, зрительного воздействия практически невозможно создать имитацию объекта, который должен располагаться, например, сверху. Этот звук должен быть как минимум привычный и ожидаемый.
Гибсон Д. в своих книгах и видео выдвигает концепцию о вертикальном расположении инструментов в музыкальном миксе по их звуковысотности (тесситуре) или форманте (область усиленных частичных тонов), так как в вертикальной плоскости звуковоспроизводящая техника построена по такому же принципу. За счет акустического кроссовера с определенными границами сложный сигнал делится на полосы частот. В трехполосной системе снизу расположен woffer предающий НЧ, в средней части mid-driver для СЧ и tweeter в верхней части системы для передачи ВЧ. А sub-woffer передает часть информации через пол. Такой подход интересен, но не подходит для многих систем, например, при использовании наушников или любой другой системы без разделения на полосы.
Подробнее с описанными принципами можно ознакомиться в книге Гибсон Д. - Визуальное руководство по звукозаписи и продюссированию.
Тем не менее уменьшение интенсивности низких частот психоакустически помогает «приподнять» объект, сделать его легче.
Перемещение источника звука
До 1960-х годов изучение способности человека локализовать источник звука в пространстве в основном касалось неподвижных источников звука. После же началось исследование восприятия человеком и движущихся источников звука: определялись основные характеристики восприятия.
В ходе исследований оказалось, что для того, чтобы у человека возникло ощущение движения звука, необходимо определенное время - временное окно. Оно колеблется от 0,08 до 0,12 с. Локализовать же короткий неподвижный звук (например, щелчок длительностью порядка 0,001 с.) достаточно легко.
Так же человек может различать скорость движения источника звука: чем она выше (в определенных пределах), тем тоньше эта способность. Если источник звука движется со скоростью 90°/с (движение по полупериметру перед головой испытуемого), человек различает изменение скорости на 15%; а при скорости движения 360°/с - на 5,5%.
Если источник является неподвижным, то для его локализации человек подсознательно совершает микроперемещения головы, на порядок повышающие точность определения положения источника в пространстве.
Эффекты
Для того чтобы правдоподобно передать звук от движущегося источника, необходимо учитывать (эффект изменения частоты звука от источника при нерадиальном перемещении его относительно слушателя). По субъективному ощущению эффекта звук резко меняет тон - становится более высоким при приближении объекта и более низким при его удалении. В игровой сфере эффект Доплера играет значимую роль. Особенно, если речь идет об авто симуляторах и других приложениях связанных с быстрым перемещением объектов. Эффект Доплера распространённым плагином для секвенсоров, а также, на сколько мне известно, существует во многих звуковых движках.
Одним из основных эффектов создания пространства является эффект реверберации (процесс многократного переотражения звукового сигнала от различных поверхностей с постепенным уменьшением его интенсивности). У моделируемой реверберации существует ряд параметров - время раннего отражения, время позднего отражения, скорость затухания, процентное соотношение «сухого» сигнала с обработанным. Эти параметры указывают на размер помещения и место источника звука в нем относительно слушателя. В работе я использую исключительно конволюционные (сверточные) ревербераторы, применяя к ним импульсы реальных помещений. Не вдаваясь в подробности технологии сам импульс представляет из себя шумовой «слепок» помещения (wav файл), который модулирует исходный звуковой файл, тем самым помещая его в имитируемое пространство. В музыкальной сфере конволюционные технологии давно используются, так в оболочке Kontakt (4,5) от NI конволюционный ревербератор с набором импульсов имеется в списке стандартных эффектов.
Звуковые системы. Бинауральная система
Существует два основных подхода по организации современных звуковых систем в помещении: многоканальные системы и двухканальные системы (в том числе и наушники). В многоканальных системах звук передается из мониторов, размещенных спереди и сзади от слушателя (либо вокруг него).
Подробно с монофоническими, бинауральными, стереофоническими и многоканальными системами и их тонкостями можно ознакомиться в книге Ю. Ковалгина - Стереофоническое радиовещание и звукозапись.
Для усиления пространственного эффекта производители пытаются продвигать концепции систем уже не пяти-, а шести-, семи- и даже девятиканальные. Увеличение количества каналов требует усложнение работы звукорежиссера, увеличения количества акустических систем, коммутационных проводов, применения более сложных усилителей, а, следовательно, позволяет увеличивать доходы с продаж.
Не всем потребителям необходимы многоканальные аудиосистемы. Для кого-то это неприемлемо по экономическим соображениям, кто-то не может выделить под систему домашних развлечений помещение в жилом помещении. Кто-то по очевидным причинам предпочитает пользоваться наушниками (в ночное время суток, при перемещении в транспорте и т.д.).
Всего два уха обеспечивают человека всей необходимой информацией об объекте, это значит, что для ее передачи достаточно всего лишь двух громкоговорителей. При использовании бинауральной записи кажущиеся источники звука в случае применения наушников оказываются вынесенными за пределы головы слушателя в то место, где расположены действительные источники звука. В отличие от этого, при прослушивании через наушники сигналов обычной стереофонии кажущиеся источники звука ощущаются как расположенные внутри головы слушателя.
Появление реверберации затрудняет оценку азимута кажущихся источников звука в тыловой области, где слушатели вместо истинного направления часто указывают соответствующее ему зеркальное фронтальное направление. Данное явление возникает особенно часто, когда время стандартной реверберации в помещении прослушивания превышает 0,3 с.
Правильная передача пространственной информации при воспроизведении с помощью двух мониторов возможна, но даже незначительное (около 9-15 см.) смещение центра головы слушателя влево или вправо от этой точки приводит к тому, что локализация кажущихся источников звука оказывается невозможной вне фокуса осей мониторов.
В оптимальной точке прослушивания бинауральная система обеспечивает звучание, уверенно предпочитаемое обычному стереофоническому. Однако ее применение весьма ограничено: воспроизведение с помощью наушников, переносная аппаратура радиовещания и звуковоспроизведения, компьютерное моделирование. Бинауральная звуковая система мало пригодна для условий коллективного прослушивания.
При воспроизведении бинаурального сигнала через акустическую систему из-за попадания сигнала правого канала в левое ухо слушателя и наоборот возникают перекрестные искажения.
В реалиях игрового саунд дизайна записанные бинауральные аудио файлы не применяются, потому как невозможно изменять их положение в пространстве, нет виртуального источника и виртуального слушателя, это не моделирование.
Алгоритмы
Основной алгоритм, использующий основные механизмы локализации звука человеком, реализован в HRTF (Head Related Transfer Functions - функции перемещения звука относительно слушателя. Количественно HRTF определяются обратным интегральным Фурье преобразованием коэффициентов под названием HRIR (Head Related Impulse Response), которые в первом приближении определяются отношением давлений на барабанную перепонку уха звуковой волны в свободном пространстве (free field) и в реальном пространстве с учётом головы человека, ушных раковин, его корпуса и других препятствий.
HRTF представляет собой сложную функцию с четырьмя переменными: три пространственных координаты и частота. При использовании сферических координат для определения расстояния до источников звука больших, чем один метр, принимается, что источники звука находятся в дальнем поле (far field),значение HRTF уменьшается обратно пропорционально расстоянию. Большинство измерений HRTF производится именно в дальнем поле, при этом количество переменных уменьшается до трёх: азимут (azimuth), высота (elevation) и частота (frequency). Действие HRTF зависит от частотного диапазона обрабатываемого сигнала: только звуки со значениями частотных компонентов в пределах от 3000 Гц до 10000 Гц могут успешно интерпретироваться с помощью функций HRTF. Если сигнал от источника звука не содержит особую частоту, влияющую на разницу между фронтальными и тыловыми HRTF функциями, то такой сигнал никогда будет локализован по направлению фронт-тыл.
HRTF моделировался при помощи манекена KEMAR (Knowless Electronics Manikin for Auditory Research) и специального «цифрового уха» (digital ear), разработанного компанией Sensaura. В ушах манекена размещаются микрофоны, а вокруг манекена - акустические колонки, в результате происходит запись того, что слышит каждое «ухо». Получаемые при таком моделировании результаты используются для пополнения базы данных по HRTF, которые затем могут быть использованы для интерактивного выбора параметров при воспроизведении позиционируемого 3D звука (в базе данных компании Sensaura накоплено более 1100 HRTF). Необходимость в такой базе данных объясняется, во-первых, различием размеров и формы головы и ушных раковин манекена и потенциального слушателя и, во-вторых, определяемых этими параметрами так называемой зоны sweet spot, в которой корректно воссоздаётся эффект звучания в вертикальной плоскости и гарантируется правильное определение местоположения источников звука в пространстве. Чем больше область sweet spot, тем большую свободу действий имеет слушатель. Поэтому разработчики постоянно ищут способы увеличить область действия sweet spot.
Компания QSound при реализации технологий с HRTF опирается не только на математические методы, но и на апробацию слушателями (таких прослушиваний было проведено около 550 тыс.). Специалисты компании Sensaura после серии опытов определили, что HRTF в чистом виде «работает» только при воспроизведении через наушники. Моделирование звука в этом случае тривиальная задача: каждый динамик контролирует соответствующее ему ухо. Однако при воспроизведении того же самого звука через колонки правое ухо слышит также звук, призванный «обманывать» с точки зрения трехмерности левое, и наоборот. Для исключения этого явления требуется добавить в звук дополнительные компенсационные вычисления. Удачные алгоритмы компенсации были разработаны, они получили название Transaural Cross-talk Cancellation (TCC). Решена задача была с помощью другой идеи инженеров Sensaura. Она заключается в том, что функции HRTF действуют только для среднестатистического уха, так как выведены с помощью одного манекена или усредненных показаний большой группы людей. Sensaura разработала цифровую модель уха, в которой можно задавать параметры ушной раковины. С помощью этой цифровой модели сочетанием разных параметров можно воспроизвести форму практически любого уха. Получившийся драйвер цифрового уха работает так: при его установке человек слушает ряд тестовых звуков и настраивает параметры драйвера, чтобы наилучшим образом ощущать трехмерность звука. Индивидуальные параметры слушателя записываются в специальный «профиль», он впоследствии и используется приложениями.
Все права в отношении данного документа принадлежат автору. Воспроизведение данного текста или его части разрешается только с письменного разрешения автора.
Ч то такое трехмерный звук и почему по этому поводу возникает так много споров? Как соотносится понятие "трехмерное, пространственное звучание" со способностью человека воспринимать звук двумя ушами? Эти вопросы часто задают себе как пользователи так и профессионалы. Дело в том, что повсеместное использование понятий 3D (3D графика, 3D звук) вносят сумятицу и неразбериху в головы простых пользователей. Зачастую эти понятия используются, мягко говоря, не совсем уместно, что вносит дополнительный раздор в их употребление и правильное понимание. 3D графика - тема не этой статьи. Здесь же мы остановимся на трехмерном звуке.
Реализация пространственного звучания (3D звука) в том или ином виде, применительно к компьютерной технике, используется для придания естественности звуку в компьютерных играх или фильмах, для создания полного ощущения погружения в процесс игры или просмотра фильма. Такая постановка задачи делает недостаточным использование обычного стереофонического звучания. Это связано с тем, что стерео сигнал, приходящий к слушателю от двух физических источников звука, не обеспечивает объемного звучания, а определяет расположение мнимых (слышимых) источников лишь в той плоскости, в которой расположены реальные (физические) источники звука. Кстати, как ни парадоксально, "stereophonic" на самом деле обозначает "трехмерный звук" (от греч. "stereos" - пространственный, трехмерный, цельный). Таким образом, обычного стерео сигнала не достаточно для создания полного реализма звучания, когда источники звука могут находиться в трехмерном пространстве. Также заблуждением является мысль, что объемное звучание обеспечивается квадрофонической системой (два источника перед слушателем и два сзади). Дело в том, что также, как и в стереофонической системе, здесь все четыре источника находятся в одной плоскости, что не позволяет создать полное ощущение трехмерного звучания.

В целом можно обозначить три основных способа реализации пространственного звучания:
расширение стерео базы (Stereo Expansion) - специальная обработка уже имеющегося стерео сигнала и, таким образом, расширение кажущегося звукового поля (имитация расширения расстояния между источниками);
позиционирование звучания (Positional 3D Audio) - оперирование с множеством отдельных звуковых потоков и расположение каждого из них в пространстве вокруг слушателя;
виртуальный (мнимый) окружающий звук (Virtual Surround Sound) - использование определенного числа звуковых потоков с целью воспроизведения истинного звучания с помощью ограниченного числа физических источников звука.
Что это все означает на практике? На практике это означает, что метод расширения стерео базы относительно прост в реализации и очень часто находит применение в стерео фонической бытовой технике. Однако, в той же степени, на сколько проста его реализация, сам метод не дает ощущения "трехмерного звучания" в том понимании, в котором мы его себе представляем, по причине обеспечения звучания лишь в одной плоскости. Не достаточно также и применения так называемого панорамирования. Панорамирование (panning) - это управление уровнем сигнала в каналах, в не зависимости от частоты сигнала. Панорамирование позволяет создавать иллюзию перемещения мнимого источника сигнала где-то между физическими источниками (разумеется, в одной с ними плоскости).
Для создания более или менее реалистичного объемного звучания необходимо что-то принципиально другое. Попытаемся в этом разобраться.
Как ни странно, но вся проблема в устройстве слухового аппарата человека. Оказывается, что он на столько не совершенен, что даже в реальной жизни мы можем столкнуться с трудностями, связанными с неточностью восприятия звуковых сигналов и определения их пространственного месторасположения. Все дело в том, что все мы живем на планете Земля и все время существования человека его основная пища и враги находились в плоскости, параллельной земле. Поэтому, два уха, расположенные по обеим сторонам головы, позволяют нам определять расположение источников звука только лишь в горизонтальной плоскости (бинауральный эффект). При этом мы очень плохо различаем звук идущий спереди и сзади. Способность оценки человеческим ухом (слуховым аппаратом) расположения источников звука в вертикальной плоскости также крайне ограничена. Кроме того, тело слушателя, в частности, голова, уши и туловище, является, как известно, препятствием на пути распространения звуковых колебаний. Взаимодействуя с телом звук отражается, затухает и искажается, что приводит к восприятию слушателем не исходного, а измененного звучания. Все это создает трудности имитации пространственного звучания.
Что же происходит внутри нас? Приемником сигнала в человеке является барабанная перепонка, скрытая ушной раковиной. При восприятии звука, мозг как бы декодирует получаемый от барабанной перепонки сигнал, интерпретируя его определенным образом для правильного определения пространственного местоположения источника/ков звука. И именно это рассуждение взято в основу всех существующих на сегодня технологий создания пространственного звучания.
Оказывается, если произвести специальную обработку звукового потока с учетом максимального числа особенностей восприятия звука слуховым аппаратом, то, возможно, удастся имитировать пространственное звучание даже с использованием всего двух источников (колонок или наушников). Необходимо подчеркнуть, что любой алгоритм создания 3D звука реализовывается с помощью алгоритмов фильтрации (оперирующих с амплитудой и частотой звукового сигнала) той или иной сложности, которые определенным образом "обманывают" слуховой аппарат, "заставляя его считать", что то, что он слышит, расположено в трехмерном пространстве вокруг слушателя.
Одним из таких алгоритмов (способов) является HRTF - Head Related Transfer Function. Посредством этого алгоритма звук можно преобразовать специальным образом, что обеспечит прекрасное 3D звучание, рассчитанное на прослушивание в наушниках (пояснение этому можно найти чуть ниже). Следует отметить, что HRTF (в том или ином виде) является основой создания множества существующих на сегодня методов создания объемного звучания. Однако мы не даром заговорили о HRTF как об одном из алгоритмов, так как этот алгоритм в чистом виде (впрочем, как и все остальные) не является единственным и совершенным. Все дело в том, что HRTF неодинаков для различного слушателя и, тем более, для различных положений головы (если речь идет о воспроизведении не через наушники). Безусловно, есть способы найти сбалансированный HRTF для всех слушателей, но такой подход не обеспечивает высокочеткое восприятие звука для каждого, и уж тем более не решает проблему с поворотами головы. Наверное, именно поэтому стандарт на HRTF не существует до сих пор.
Конечно, если в качестве источников звука будут выступать наушники, закрепленные на голове слушателя, то их расположение относительно головы слушателя не будет изменяться, какие бы повороты головы не производились. В этом случае, как мы сказали, с использованием HRTF может быть достигнуто высококачественное пространственное звучание. В случае же, если источниками являются, например, две колонки, то, кроме всего прочего, для создания естественного пространственного звучания необходимо, в частности, точно отслеживать повороты слушателем головы для соответствующей корректировки сигналов от каждого физического источника. Кроме того, при воспроизведении звука через наушники, сигнал от каждого канала попадает только в соответствующее ухо, а при воспроизведении через колонки сигналы могут смешиваться, в результате чего появляются перекрестные искажения. Этот недостаток частично устраняется с помощью специального устройства - бифонического процессора.
Итак, как мы сказали выше, при использовании в качестве источников звука колонок, возникает проблема необходимости расположения слушателя строго в определенной области пространства между источниками звука. Эта область называется Sweet Spot. При отсутствии возможности контролировать положение слушателя в пространстве относительно источников звука при прочих равных условиях, Sweet Spot накладывает строгие ограничения на расположение слушателя. Это значит, что как только слушатель покидает область Sweet Spot, звучание, создаваемое источниками, перестает восприниматься слушателем как пространственное. Поэтому, при создании технологий объемного звучания перед разработчиками возникает проблема расширения области Sweet Spot.
Одним из эффективных методов решения этой проблемы является введение дополнительного третьего источника звука, когда слушатель становится независимым от области Sweet Spot. Трехканальные системы объемного звучания часто используются в бытовой аудио и видео аппаратуре. Существуют также многоканальные (трех-, четырех- и более) расширения этого метода.
Однако наряду с проблемами реализации трехмерного звучания с помощью HRTF, у любой системы звуковоспроизведения есть проблемы другого плана. Так, например, наушники слабо справляются с воспроизведением фронтальных сигналов. При использовании наушников также возникает проблема локализации звукового сигнала внутри головы слушателя, а также эффект бесконечного расширения стерео базы. Конечно, существуют способы борьбы с этими эффектами, однако всех проблем это не решает. Двухканальные системы плохо обеспечивают восприятие слушателем звучания сзади. В реализации многоканальных систем слабым местом является необходимость достаточно точного расположения источников сигнала, потому что как раз это зачастую сделать затруднительно. Кроме того, здесь также существует проблема звучания в одной плоскости.
Таким образом, создание настоящего качественного пространственного звучания затруднено как необходимостью учитывать все особенности слухового аппарата человека, так и необходимостью динамического отслеживания положения слушателя относительно источников звука, а также учета особенностей звукопередачи последних. По этому, сложно сказать, какая схема создания 3D звука более совершенна. Гораздо легче сказать, что все существующие схемы далеки от совершенства, и все технологии 3D звука, построенные на использовании HRTF или других алгоритмов, имеют массу недостатков, так как просто невозможно создать универсальную схему, учитывающую все вышеперечисленные особенности слуха, источников звука и их расположения относительно слушателя.
В качестве справки отметим, что для создания библиотек HRTF используется искусственный манекен KEMAR (Knowles Electronics Manikin for Auditory Research) или специальное "цифровое ухо". В случае использования манекена суть измерений состоит в следующем. В уши манекена встраиваются микрофоны. Звук воспроизводится источниками, расположенными вокруг манекена, а запись производится с микрофонов. В результате, запись от каждого микрофона представляет собой звук, "прослушанный" соответствующим ухом манекена с учетом всех изменений, которые звук претерпел на пути к уху. Расчет HRTF производится с учетом исходного звука и звука, "услышанного" манекеном.
Следует сказать также, что мы рассмотрели лишь одну сторону реализации полноценного пространственного звучания. Дело в том, что на ряду со сложностями, связанными с "правильной" передачей объемности звучания, при создании игр возникают также проблемы корректной имитации различных физических свойств звука (эффектов отражения от различных поверхностей, поглощения и искажения звука). Грамотная реализация этих свойств также коренным образом влияет на ощущение слушателем пространственности звучания. Однако, эта проблема в основном касается аккуратности механизмов, закладываемых разработчиками в игры. Что же касается рассмотренной нами выше проблемы <донесения> трехмерного звука до пользователя (а вернее, до его нервной системы), то она остается не решенной, так как идеальные модели реализации трехмерного звучания еще не найдены.
Совсем недавно можно было наблюдать, как в мир коммерческих и домашних кинотеатров пришло стереокино, а сейчас на очереди уже стоит видео сверхвысокого разрешения 4K. От изображения не отстает и звук: в домашний кинотеатр пришло 3D Audio, полное звуковое окружение зрителя — не только в горизонтальной плоскости, но и в третьем измерении. В английском языке для этого применяется термин immersive, «погружающий».
Глас божий и другие аудиоканалы
Формат Auro-3D был представлен в мае 2006 года бельгийской компанией Galaxy Studios. Первым массовым фильмом, записанным в данном формате, стала лента Red Tails («Красные хвосты»), снятая в 2012 году Джорджем Лукасом. Принципиальное отличие Auro-3D от преобладавших на тот момент форматов Dolby Surround EX и DTS заключалось в том, что кроме традиционных каналов 7.1, расположенных в одной плоскости, разработчики предложили использовать третье измерение — то есть разместить акустические системы (АС) не просто вокруг слушателя, но и сверху, вторым «слоем», под углом в 30 градусов к фронтальным акустическим системам и каналам окружающего звучания.
Дальнейшее усовершенствование формата привело к появлению еще одного «слоя» — над головами слушателей, который символично назвали voice of god («глас божий»). Максимальное количество каналов (не стоит путать с количеством акустических систем) при этом достигло 13.1, то есть фактически стало в два раза больше, чем в применяемых тогда форматах 7.1 и 6.1. Внедрение верхних каналов позволило более точно передать ряд событий в звуковой дорожке фильма, таких как пролеты объектов над зрителями (шум вертолета или реактивного истребителя), атмосферные эффекты (завывание ветра, раскаты грома).
 Если потолок расположен слишком низко, акустика будет слишком близко к зрителю. В этом случае Dolby рекомендует использовать специальные акустические системы, работающие «на отражение» от потолка — по утверждению компании, результат будет более качественным.
Если потолок расположен слишком низко, акустика будет слишком близко к зрителю. В этом случае Dolby рекомендует использовать специальные акустические системы, работающие «на отражение» от потолка — по утверждению компании, результат будет более качественным.
Объектный подход
Старейший игрок на рынке кинотеатрального звука, компания Dolby Laboratories, использует в своем новом формате Dolby Atmos два «слоя» акустических систем. Первый располагается вокруг слушателя по классической схеме, а второй на потолке — попарно слева и справа. Но самое главное — принципиально новый подход к микшированию саундтреков. Вместо привычного поканального сведения в студии используется метод «объектной» записи. Режиссер работает со звуковыми файлами, указывая место в трехмерном пространстве, откуда эти звуки должны воспроизводиться, когда и с какой громкостью. К примеру, если необходимо воспроизвести шум движущейся машины, то режиссер указывает время появления, уровень громкости, траекторию движения, место и время прекращения звучания «объекта».
Более того, из студии в кинозал звук попадает не в виде записанных дорожек, а как набор звуковых файлов. Эта информация обрабатывается процессором, который в реальном времени каждый раз просчитывает саундтрек фильма с учетом количества АС в зале, их типа и расположения. Благодаря точной калибровке нет привязки к какому-то «типовому» количеству каналов, и можно использовать в разных залах разное количество АС (каждый зал калибруется и настраивается индивидуально) — процессор сам просчитает, как и куда нужно отправить звук для получения оптимальной звуковой панорамы. Максимальное количество одновременно обрабатываемых звуковых «объектов» составляет 128, а количество одновременно поддерживаемых независимых АС — до 64.
 Формат Dolby Atmos не привязан к конкретному количеству аудиоканалов. Звуковая картина формируется процессором в реальном времени из «объектов» и по «программе», составленной звукорежиссером фильма. При этом процессор учитывает точное расположение акустических систем, их тип и количество — все это заранее прописывается в настройках при калибровке каждого конкретного зала. Правда, как такой подход реализовать в домашнем кинотеатре, пока не совсем понятно.
Формат Dolby Atmos не привязан к конкретному количеству аудиоканалов. Звуковая картина формируется процессором в реальном времени из «объектов» и по «программе», составленной звукорежиссером фильма. При этом процессор учитывает точное расположение акустических систем, их тип и количество — все это заранее прописывается в настройках при калибровке каждого конкретного зала. Правда, как такой подход реализовать в домашнем кинотеатре, пока не совсем понятно.
Профессионалы и любители
Вслед за появлением в коммерческих кинозалах оба формата трехмерного звука начали завоевание домашнего рынка. Auro-3D стартовал чуть раньше, несколько производителей домашней электроники представили первые процессоры и ресивер с поддержкой формата еще в начале 2014 года. Dolby Laboratories не заставила себя долго ждать, и в середине сентября прошлого года представила весьма доступные решения на базе недорогих ресиверов. Кроме того, в начале 2015 года еще один крупный игрок, американская компания DTS, анонсировала свой формат трехмерного звучания — DTS: X (о котором известно пока только то, что он, как и Dolby Atmos, является объект-но-ориентированным и будет поддержан многими производителями бытовой электроники).
Между тем, коммерческое и домашнее кино в некоторых аспектах имеют серьезные отличия. Бобины с кинопленкой ушли в далекое прошлое, и в кинопрокате в настоящее время практически повсеместно используются цифровые копии фильмов. Саундтрек к фильму «выходит» из сервера в виде потока цифрового аудио с высоким битрейтом и практически без сжатия. Серверы, на которых хранятся фильмы, могут передавать до 16 цифровых каналов таких данных параллельно.

Самый популярный носитель для домашнего кино — Blu-ray диск. Как правило, он содержит саундтрек, записанный в одном из двух самых популярных форматов — DTS HD Master Audio или Dolby True HD. Встречаются и диски, записанные с использованием старых кодеков DTS и Dolby Digital со звуком 2.1 (лево-право и LFE). Если дорожка к фильму изначально была записана в студии в формате 5.1 или 7.1, перенести ее на диск довольно просто, отличие лишь в дополнительной компрессии данных, связанной с ограниченной емкостью цифрового носителя. А как же будут адаптироваться новые форматы Auro-3D и Dolby Atmos при переносе их из профессионального кино в домашний кинозал?
Путь домой
Для Auro-3D перенос будет практически «бесшовным». Если фильм изначально записан в студии в формате 13.1 или 11.1, ровно с таким же количеством каналов он и будет переноситься на диски Blu-ray. Для обратной совместимости в Auro-3D используется специальный алгоритм, который умеет «дописывать» верхние каналы в кодек DTS HD MA, официально поддерживающий максимум 7.1 каналов — например, в левый канал инкапсулируется информация для верхнего левого канала, в центральный — для верхнего центрального и т. д. Если в ресивере или процессоре есть поддержка декодирования кодека Auro-3D, то он «вынет» вложенную информацию и подаст ее на соответствующие каналы. Если нет — просто декодирует данные как обычную дорожку 7.1, пропустив «лишнюю» информацию. Таким образом, диск с фильмом в формате Auro-3D в любом случае будет корректно прочитан любым современным плеером и распознан любым из процессоров или ресиверов, поддерживающих DTS HD MA. А если процессор или ресивер обладает встроенным декодером Auro-3D, то на выходе можно получить саундтрек из 9.1, 11.1 или даже 13.1 каналов. Существует и возможность «апмиксинга» (upmixing) — процессор, умеющий работать с Auro-3D, может пересчитать даже обычную двухканальную стереозапись, скажем, в 13.1.
 В Auro-3D используется трехслойное расположение акустических систем и более традиционный подход с многоканальной записью звука. Это обеспечивает отличную обратную совместимость стандарта с текущими форматами и переносимость на домашние системы.
В Auro-3D используется трехслойное расположение акустических систем и более традиционный подход с многоканальной записью звука. Это обеспечивает отличную обратную совместимость стандарта с текущими форматами и переносимость на домашние системы.
Ситуация с Dolby Atmos в домашнем кинотеатре намного более сложная: процессор в реальном времени обсчитывает довольно большой поток данных и выдает звук на соответствующие акустические каналы (с учетом того, сколько их в конкретной инсталляции). На текущий момент спецификациями Dolby Atmos для домашнего применения предлагается использовать конфигурации АС от 5.1.2 до 7.1.4, где первая цифра — это количество «обычных» каналов: левый-центр-правый-боковые-тылы, вторая — это канал низкочастотных эффектов, а третья — так называемые «верхние» каналы (overhead). При этом единственный процессор для коммерческого применения (Dolby CP850) стоит более миллиона рублей, а стоимость домашних ресиверов с поддержкой Atmos начинается всего от 30−40 тысяч. Тем не менее даже для самых доступных по цене домашних ресиверов заявлены и декодирование, и поддержка «апмиксинга», хотя как именно это сделано, не совсем понятно.
Еще один не очень ясный момент заключается в том, что для правильного обсчета звукового поля необходимо знать точное местоположение всех акустических систем. В коммерческом кинотеатре этот вопрос решается калибровкой аппаратуры, а вот в домашних ресиверах, насколько известно, такой возможности не предусмотрено. Как в таком случае решается вопрос о получении дома полноценного звучания Atmos «как в кино», пока неясно. Правда, формат пока еще не обрел окончательные черты. Несколько производителей процессоров премиум-класса даже отложили выпуск обновлений с поддержкой Dolby Atmos из-за изменений в алгоритме обработки сигнала, вносимых, по их словам, разработчиками Dolby. Так что можно предположить, что в последующих обновлениях Dolby может внести коррективы в процесс обработки звука и/или калибровки системы под конкретное расположение акустических систем.

Вопросы совместимости
Поскольку Auro-3D использует традиционный метод поканального сведения, а Dolby и DTS — объектно-ориентированный монтаж звука, переконвертировать один формат в другой невозможно. Кроме того, построить домашний кинотеатр, умеющий правильно работать со всеми форматами, тоже непросто. Проблема совместимости заключается в различных требованиях к установке акустических систем. В Dolby Atmos используется два «слоя» акустики, а в Auro-3D — три. Можно было бы предположить, что саундтрек Dolby Atmos может быть воспроизведен через часть АС для проигрывания Auro-3D, но вряд ли это будет корректно. Требования для расположения АС весьма жесткие у обоих форматов, а учитывая чувствительность к точному позиционированию для получения плавных переходов, это может стать проблемой для проектировщиков и инсталляторов домашних кинозалов (информации по расположению акустики DTS: X пока нет).

Перспективы
Несмотря на все неясности описания Dolby Atmos, нужно признать, что этот формат имеет больший потенциал, чем Auro-3D. Во‑первых, объектно-ориентированный подход к записи однозначно более перспективен, чем традиционный поканальный. Во вторых, поддержка Dolby Atmos в массовых моделях AV-ресиверов таких фирм, как Yamaha, Pioneer, Onkyo, Integra, Denon, доступна «в базе», в то время как лицензию на Auro3D придется покупать как опциональное программное обновление за $199, что ощутимо для бюджетных моделей.
В более дорогом сегменте процессоров для построения домашних кинозалов о поддержке всех форматов 3D Audio заявили и такие производители, как Trinnov Audio и Datasat Digital, работающие в том числе и на коммерческом кинорынке. Их опыт может весьма благотворно сказаться на реализации Dolby Atmos для домашнего кинотеатра: например, Trinnov для калибровки своих процессоров использует уникальный трехмерный микрофон, позволяющий точно определить место каждой АС в пространстве и применять эти данные для дополнительной коррекции звукового поля.
Редакция благодарит журнал avreport.ru за помощь в подготовке статьи.
Развитие систем объемного звучания - от монофонии к 3D
В настоящее время двухканальная стереофония стала уже классическим способом передачи и воспроизведения звука. Целью стереофонического звуковоспроизведения является максимально точная передача звукового образа. Локализация звука при этом является лишь средством, позволяющим получить более богатое и естественное звучание. Однако передача пространственной информации наиболее распространенными "классическими" двухканальными системами имеет ряд недостатков, что побуждает конструкторов к созданию различных систем объемного звучания.
Слушатель, находящийся в концертном зале слышит не только прямой звук, исходящий от отдельных инструментов оркестра, но и приходящий с различных направлений (в том числе и сзади) отраженный от стен и потолка помещения рассеянный (диффузный) звук, который создает эффект пространства и дорисовывает общее впечатление. Запаздывание, с которым диффузный звук достигает ушей слушателя, и его спектральный состав зависят от размера и акустических свойств помещения. При двухканальной передаче информация, создаваемая диффузным звуком, в значительной степени теряется, а в случае студийной записи может отсутствовать изначально.
Человеческое ухо лучше всего локализует источники звука в горизонтальной плоскости. При этом звуки приходящие сзади, при отсутствии дополнительной информации локализуются хуже. Зрение, в том числе и периферийное, является основным чувством определения местоположения объектов, поэтому без зрительной информации возможность оценки положения звука в вертикальной плоскости и его удаленности от нас слаба и достаточно индивидуальна. Отчасти это можно объяснить индивидуальными анатомическими особенностями ушных раковин. При воспроизведении записей зрительная информация отсутствует, поэтому любая звуковая технология для массового рынка, претендующая на "объемное звучание", вынуждена создавать нечто усредненное и заведомо компромиссное.
Для воспроизведения или синтезирования "эффекта зала" можно использовать множество способов. Еще в середине 50-х годов фирмами Philips, Grundig, Telefunken были опробованы системы трехмерного воспроизведения 3D и Raumton. Передача звука была монофонической, но дополнительные громкоговорители (обычно встроенные, реже - выносные), излучающие звук вбок или вверх, создавали за счет отраженного от стен и потолка звука впечатление большого пространства. Поскольку задержка эхо-сигнала в бытовых помещениях достаточно мала, для ее увеличения позднее использовались пружинные ревербераторы в канале усиления дополнительных сигналов. Эти системы ввиду значительной для того времени технической сложности продержались на рынке недолго и быстро сошли со сцены.
В дальнейшем для передачи диффузного звука были разработаны амбиофонические системы, нашедшие применение, главным образом, в кино. Дополнительный канал (или каналы) для передачи диффузного звука в таких системах имеют меньшую мощность, чем основные, а их частотный диапазон соответствует полосе частот диффузного сигнала (примерно 300...5000 Гц). Излучение дополнительных динамиков должно быть рассеянным, для чего они направлены на стены или потолок помещения прослушивания.

Сложность стандартизации и технические проблемы с записью и передачей сигналов трех, четырех и более каналов привели к тому, что основной системой записи и передачи звука на долгие годы стала двухканальная стереофония. Но попытки создания систем объемного звучания не прекращались. Развитием амбиофонии стала квадрафония (четырехканальное звуковоспроизведение), пик популярности которой пришелся на первую половину 70-х годов. В отличие от амбиофонической системы здесь все каналы воспроизведения звука оборудованы равноценно. Дискретная (полная) квадрафония, обеспечивающая максимальный эффект присутствия, требует четырех каналов передачи звука и в силу этого оказалась несовместимой с существовавшими в тот момент техническими средствами звукозаписи и радиовещания.

Для преодоления этого препятствия было создано несколько систем матричной квадрафонии (по терминологии того времени - квазиквадрафонии), в которых исходные сигналы четырех каналов матрицировались для передачи по двум каналам, а при воспроизведения исходные сигналы восстанавливались путем суммарно-разностных преобразований, причем без декодера можно было воспроизводить обычный стереосигнал. Поскольку ни одна из этих систем не была ни полноценно квадрафонической, ни полностью совместимой с двухканальной стереофонией из-за большого проникновения сигналов из канала в канал, практическое их применение было ограниченным и интерес к ним быстро угас.

В "войне стандартов" квадрафонических систем победителей не было, идея благополучно скончалась, принципы позабылись, а термин остался. Поэтому сейчас мало кого смущает тот факт, что "нечто", имеющее четыре канала усиления и четыре колонки гордо именуется "квадрафонической системой". Однако это в корне неправильно, поскольку источник сигнала остается двухканальным, а сигналы фронтальных и тыловых каналов при таком построении системы отличаются друг от друга только уровнем, то есть используется принцип панорамирования.
Панорамирование при производстве стереозаписей широко применялось уже с середины 50-х годов для расположения монофонических звуковых сигналов "слева/справа/в середине" звукового поля. При панорамировании не оказывается никакого воздействия на частоту и фазу сигнала, изменяется только уровень монофонического сигнала, подводимого к каждому из стереоканалов. Панорамирование на несколько каналов (в случае многоканальных записей) осуществляется аналогично. Однако при определении направления на источник звука наш слуховой аппарат использует не только разность интенсивности звуковых сигналов, но и фазовый сдвиг между ними, причем влияние фазового сдвига на точность локализации источника звука наиболее ярко выражено в области частот приблизительно от 500 до 3000 Гц. (Опять диапазон частот диффузного звука!).
Поэтому простое панорамирование не обеспечивает нужной достоверности звучания. Стереоэффекты ("бегающий звук", привязка звука "слева-справа" и т.д.) первых стереозаписей достаточно быстро приелись. Поэтому лучшие записи электронных инструментов в студии в 60-е годы проводились с использованием микрофонной техники, что объясняет "живой" характер звучания: Внедрение многоканальной полностью электронной (без использования микрофонов) записи инструментов с последующим сведением, облегчив работу звукорежиссера, одновременно уничтожило атмосферу зала. В последующем этот факт стал учитываться при проведении студийных записей, хотя полного возврата к микрофонной технике не произошло.
При использовании двухканальной схемы воспроизведения основная зона эффективного расположения кажущихся источников звука (КИЗ) находится спереди от слушателя и покрывает пространство порядка 180 градусов в горизонтальной плоскости. Два фронтальных канала не в состоянии адекватно воспроизвести звуки, источники которых в реальности расположены сзади и в вертикальной плоскости, если нет поддержки в виде дополнительных сигналов. Применение тыловых акустических систем в сочетании с панорамированием звука хорошо справляется с расположением источников звука спереди и сзади от слушателя и слабее с боковым расположением. Однако само по себе панорамирование звука никогда не сможет обеспечить приемлемое позиционирования источников звука в вертикальной плоскости.
В ходе разработки матричных систем выяснилось, что значительная часть пространственной информации содержится в разностном сигнале (сигнале стереоинформации), который можно подать на громкоговорители тыловых каналов или в чистом виде, или в смеси с некоторой долей фронтальных сигналов. В простейшем случае для этого даже не нужны дополнительные каналы усиления, а матрицирование сигналов можно провести на выходе усилителя:

Так появились на свет несколько псевдоквадрафонических систем, полностью вытеснивших "истинных арийцев" с рынка в середине 70-х. Они отличались друг от друга только способами получения разностного сигнала. Впрочем, их триумф тоже был недолгим, что объяснялось недостатками носителя сигнала - винилового диска и магнитной ленты. Некоррелированные шумы левого и правого каналов не вычитались, что в сочетании с относительно невысоким уровнем разностного сигнала сильно ухудшало отношение сигнал/шум в тыловых каналах.
Другой, не менее существенный недостаток подобных систем - отсутствие зависимости уровня тылового сигнала от характера фонограммы. При малом уровне тылового сигнала пространственный эффект мало заметен, при увеличении уровня появляется разрыв звуковой сцены и перемещение ее фрагментов назад (эффект "окружения оркестром", не соответствующий действительности).
При воспроизведении "живых" записей (имеющих естественное распределение суммарных, разностных и фазовых составляющих) этот недостаток проявлялся незначительно, но на большинстве студийных фонограмм тыловые каналы вносили значительные ошибки в положение КИЗ. Для устранения этого недостатка в ранних системах объемного звучания пытались применить автоматическое панорамирование. Управляющие сигналы получали из уровня пространственной информации - возрастание уровня разностных сигналов приводило к увеличению усиления в тыловых каналах. Однако принятая модель панорамирования была очень грубой, в результате чего ошибки регулирования экспандера приводили к хаотическому изменению уровня тыловых сигналов (эффект "тяжелого дыхания").
Интерес к системам объемного звучания вновь возник с появлением цифровых носителей информации, уровень собственных шумов которых пренебрежимо мал и даже аналоговая обработка сигнала практически не ухудшит динамический диапазон системы. Развитие цифровых методов обработки сигнала привело к созданию цифровых звуковых процессоров (Digital Sound Processor - DSP).
Разработанные первоначально для систем "домашнего театра" процессоры объемного звучания в последнее время начали активно использоваться и в автомобильных аудиосистемах. Их применение позволяет значительно улучшить звучание в салоне автомобиля, поэтому они выпускаются не только в виде отдельных DSP-устройств, но и входят в состав относительно недорогих магнитол. Настройки процессоров позволяют выбрать наиболее оптимальные параметры для выбранного места прослушивания.
Существует ряд методов, позволяющих аппаратуре воспроизводить звук, локализуемый в пространстве, при ограниченном количестве акустических систем. Разные методы реализации имеют сильные и слабые стороны, поэтому важно понимать принципиальные различия между основными методами обработки сигнала. В основе современных систем пространственного звучания (Dolby Surround, Dolby Pro-Logic, Q-Sound, Curcle Surround и других) лежит все та же идея суммарно-разностного преобразования, дополненная "фирменными" методами обработки сигналов (как аналоговыми, так и цифровыми). Часто их объединяют общим названием "3D-системы" ("второе рождение" термина сорокалетней давности!).
Прежде чем рассматривать принципы, используемые при обработке звуковых сигналов в системах объемного звучания, вспомним типичный процесс создания записи. Сначала производится запись, имеющая много индивидуальных каналов -- инструменты, голоса, звуковые эффекты и т.д. Во время микширования для каждой звуковой дорожки контролируется уровень громкости и расположение источника звука для достижения требуемого результата. В случае стереозаписи результатом микширования являются два канала, для surround-систем число каналов больше (например, 6 каналов для формата "5.1" Dolby Digital/AC-3). В любом случае, каждый канал состоит из сигналов, которые предназначены для направления в отдельные колонки при прослушивании пользователем. Каждый из этих сигналов представляет собой результат сложного микширования сигналов исходных источников.
Далее происходит процесс кодирования каналов, полученных после микширования и в результате получается один цифровой поток (bitstream). При проигрывании декодер обрабатывает цифровой поток, разделяя его на индивидуальные каналы и передавая их для воспроизведения на акустические системы. Для многоканальных (дискретных) систем объемного звучания при этом возможен режим имитации реально отсутствующих акустических систем (Phantom mode). Если у вас всего две колонки, тогда канал сабвуфера (низкочастотный) и центральный (диалогов) просто добавляются одновременно к обоим выходным каналам. Задний левый канал добавляется к левому выходному каналу, задний правый к правому выходному каналу.
Вспомним, что панорамирование воздействует только на амплитуду звукового сигнала. Преобразование звука в современных 3D-системах включает в звуковой поток дополнительную информацию о амплитуде и разности фаз/задержке между выходными каналами. Обычно степень обработки зависит от частоты сигнала, хотя некоторые эффекты создаются с использованием простых задержек по времени.
Какие же методы используются для обработки звукового сигнала? В первую очередь это расширение стереобазы (Stereo Expansion), которое производится путем воздействия на разностный стереосигнал фронтальных каналов. Этот метод можно считать классическим и он применяется прежде всего к обычным стереозаписям.
Обработка сигнала может быть как аналоговой, так и цифровой. Во-вторых, Positional 3D Audio (локализуемый 3D звук). Этот метод оперирует с множеством отдельных звуковых каналов и пытается индивидуально определить местоположение каждого сигнала в пространстве. В-третьих, Virtual Surround (виртуальный окружающий звук) - метод воспроизведения многоканальной записи с использованием ограниченного числа источников звука, например воспроизведение пятиканального звука на двух акустических колонках. Очевидно, что два последних метода применимы только к многоканальным звуковым носителям (записи в формате DVD, AC-3), что пока для автомобильных систем не очень актуально.
Замыкают список различные методы искусственной реверберации. Когда звук распространяется в пространстве, он может отражаться или поглощаться различными объектами. Отраженные звуки в большом пространстве могут в реальности создавать ясно различимое эхо, но в ограниченном пространстве происходит совмещение множества отраженных звуков так, что мы слышим их как единую последовательность, которая следует за исходным звуком и затухает, причем степень затухания различна для разных частот и напрямую зависит от свойств окружающего пространства.
В цифровых звуковых процессорах используется обобщенная модель реверберации, что сводит управление процессом реверберации к заданию ключевых параметров (время задержки, количество отражений, скорость затухания, изменение спектрального состава отраженных сигналов). Таким образом реализуются режимы hall, live, stadium, и т.д. Имитация получается достаточно реалистичной. В аналоговых процессорах для этой цели используются линии задержки сигнала. Управление параметрами реверберации в этом случае значительно сложнее, поэтому обычно имеется только один фиксированный режим работы.
Конечно, изложить особенности строения всех существующих систем объемного звучания трудно, но их работа основана на рассмотренных принципах - различие только в деталях алгоритмов и наборе режимов (предустановок). Поэтому лучший советчик при выборе звукового процессора - собственный слух.